
Recentemente eu li um artigo super interessante no blog do Regis A. Ely. Basicamente, ele utilizou os dados da pesquisa que o movimento “vem para a rua” está realizando sobre as intenções de votos no impeachment, para tentar criar um modelo de predição para a votação dos deputados indecisos. Eu achei super interessante, e pelo que eu vi, muita gente está compartilhando no Facebook.
ENTRETANTO, eu fiquei curioso com relação a alguns pontos na análise e em relação às escolhas que ele fez. Minhas críticas em relação a análise são:
1 – Será que somente o partido e o estado de origem são suficientes para fornecer uma boa previsão?
2 – Qual o real desempenho do modelo?
3 – Que outros insights os dados podem fornecer?
4 – Os deputados já decididos representam bem os indecisos?
A primeira questão é super importante, pois na verdade a ideia toda da análise é que um modelo onde eu sei somente o partido e o estado de origem do deputado (ou senador) é suficiente para fornecer uma boa previsão. O modelo também utiliza o pressuposto de que os deputados que já decidiram o voto representam bem todos os deputados, tal que uma vez que eu crie um modelo que aprenda a partir deles eu serei capaz de prever com segurança o voto dos outros, dos indecisos.
A segunda questão me deixou bastante curioso, pois ele usou uma poda na árvore de decisão, mas pelo que eu vi ele não reportou o desempenho real em um pequeno conjunto de teste. Isso seria importante pois para confiar nas previsões de um modelo é bom saber aproximadamente qual será o desempenho do modelo.
O terceiro ponto talvez seja o que eu acho que seria o mais importante de se fazer: uma pequena análise exploratória. Eu sei que as árvores de decisão são super interpretáveis, e que apesar de podermos pensar nelas como um modelo, “de uma certa forma” elas poderiam ser encaradas como um tipo de “análise exploratória”. ENTRETANTO, eu não gosto muito de criar modelos antes de “dar uma olhada” nos dados. E acredito que o principal resultado da análise, que foi mostrar como era a influência dos partidos, pode ser facilmente obtido por meio de algumas visualizações.
Análise Exploratória
O que eu fiz foi basicamente pegar os dados no site do Regis e fazer algumas visualizações. Para não dizer que eu não adicionei nada, eu adicionei também a região e fiz um scrape no site do “vem pra rua” para incluir a variável sexo no conjunto de dados. Todos os resultados que eu vou apresentar se referem somente à câmara dos deputados.
Minha primeira dúvida era com relação ao tamanho da bancada de cada partido na câmara, isto é, quais partidos tem mais deputados? 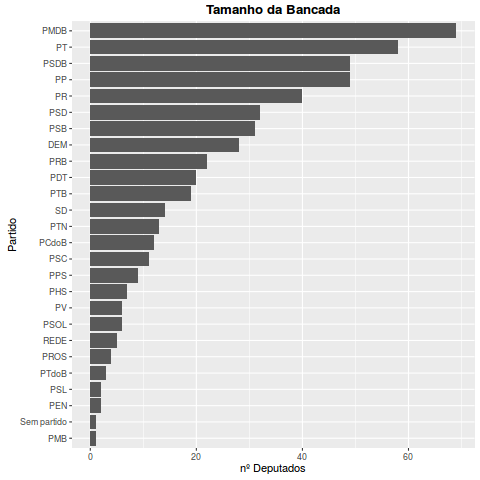
Muita gente que não acompanha a política as vezes fica surpresa com o tamanho da bancada do PMDB, mas o FATO é que o PMDB é o maior partido da câmara e é justamente esse partido que deve decidir o impeachment. Veja que o PT tem a segunda maior bancada e pasmem para o tamanho do PP e do PR…(sim o PP é do Paulo Maluf!)
Depois que eu vi esse gráfico logo pensei: ok, o PT deve votar em massa contra, o PSDB em massa a favor, mas e o resto? Como está até agora a distribuição? Vamos ver!
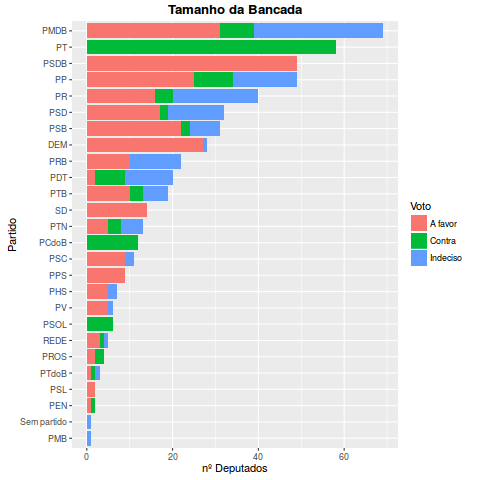
Esse é praticamente o mesmo gráfico anterior, mas com a informação adicional de como está divido o partido. Veja que o PMDB está rachado: além de ter uma parcela que é contra, o partido ainda tem uma parte significativa de indecisos. A forma como o PMDB vai votar vai selar o destino da Presidente Dilma. O PT naturalmente vota contra em massa, e sendo a segunda bancada isso pesa fortemente a favor da presidente, mas o PP, o PR, o PSD, PRB e PDT ainda tem um contingente enorme de indecisos. É por isso que a presidente está distribuindo ministérios a rodo na tentativa de angariar esse votos. Um desembarque do PP do governo também pode ser um golpe de misericórdia.
Além do partido do deputado, o estado de origem também é uma variável que vai entrar no modelo. Vamos ver como anda a distribuição em relação ao estado e a região.
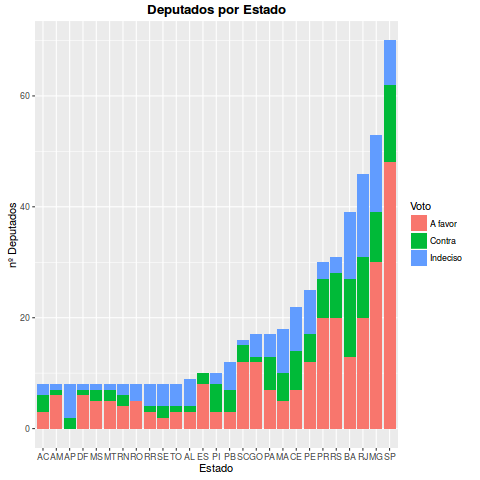
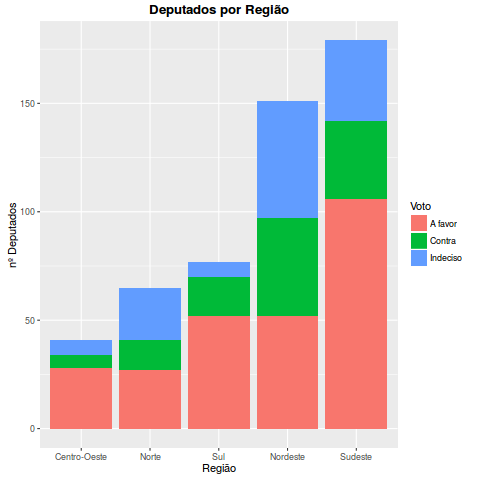
Vejam que o estado de São Paulo tem uma quantidade muito grande votos a favor. Isso se deve principalmente ao PSDB que é forte no estado e tem uma bancada que vota em massa no impeachment. NO ENTANTO, na Bahia, no Rio, em Minhas e em São Paulo mesmo, ainda há muitos indecisos. Esses estados vão ter um papel fundamental. Vejam que o Sul e o Centro-Oeste votam em peso a favor, e tanto o nordeste quanto o norte ainda estão bastante divididos.
Uma questão que eu fiquei intrigado, e para ser honesto eu não sabia de antemão, eram quantas mulheres são deputadas na câmara. Mais que isso, eu fiquei me perguntando se talvez as deputadas teriam uma distribuição diferente em relação aos homens. Primeiramente gostaria de destacar que existem muito poucas mulheres na câmara (54 sendo que 2 não estão em exercício) e ainda que elas votassem diferente, ainda assim, provavelmente não teriam um impacto tão grande. Nos modelos que eu testei o sexo de fato não teve um peso grande. MAS vamos ver a distribuição:
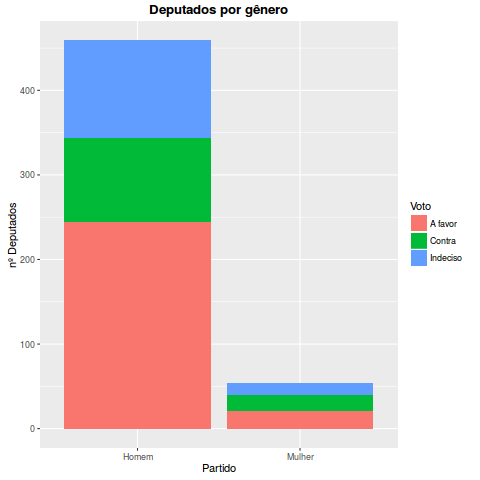
Bem divido, como no caso dos homens.
Modelagem
Para a etapa de modelagem eu fiz uma amostra aleatória de 95 observações (3/4) que eu deixei para teste. Daí eu criei 4 modelos, com as 289 observações restantes, utilizando árvores de decisão, regressão logística, randomForest e Gradiente Boosting. A especificação foi: Estado + Partido + Estado:Partido. ISTO É, as duas variáveis mais o efeito de interação. A ideia da interação é porque, de repente, um deputado, mesmo sendo do mesmo partido, vota diferente dependendo da região. Essa hipótese é plausível e por isso eu coloquei.
A seguir o resultado do ajuste do RandomForest (só um exemplo) e a seguir eu apresento as acurácias globais e o intervalo de confiança 95% para a acurácia de predição no conjunto de teste. Vejam que eu deixei de fora todos os deputados indecisos. Portanto o ajuste foi com uma variável resposta com duas classes, contra e a favor.
Random Forest
289 samples
8 predictors
2 classes: 'A favor', 'Contra'
No pre-processing
Resampling: Cross-Validated (10 fold)
Summary of sample sizes: 260, 260, 260, 260, 261, 260, ...
Resampling results across tuning parameters:
mtry Accuracy Kappa Accuracy SD Kappa SD
2 0.6885468 0.0000000 0.003504988 0.0000000
35 0.9066502 0.7614794 0.039824877 0.1142898
647 0.9135468 0.7786241 0.046595216 0.1308177
Accuracy was used to select the optimal model using the
largest value.
The final value used for the model was mtry = 647.
Eu estou utilizando o pacote caret, tal que o modelo é ajustado com os melhores hipeparâmetros obtidos por validação cruzada. Segundo o resultado obtido por validação cruzada, o desempenho do modelo deve ficar na casa dos 90%. Vamos verificar isso no conjunto de teste.
Confusion Matrix and Statistics
Reference
Prediction A favor Contra
A favor 63 8
Contra 3 21
Accuracy : 0.8842
95% CI : (0.8023, 0.9408)
No Information Rate : 0.6947
P-Value [Acc > NIR] : 1.207e-05
Kappa : 0.7131
Mcnemar's Test P-Value : 0.2278
Sensitivity : 0.9545
Specificity : 0.7241
Pos Pred Value : 0.8873
Neg Pred Value : 0.8750
Prevalence : 0.6947
Detection Rate : 0.6632
Detection Prevalence : 0.7474
Balanced Accuracy : 0.8393
'Positive' Class : A favor
Vejam que a sensibilidade é alta, mas a especificidade não (a classe de referência é o voto a favor). Isso indica que o modelo é bom em detectar o voto a favor, mas não tão bom para detectar o voto contra. Isso deve estar acontecendo, dentro outras razões, poque o conjunto é desbalanceado em relação aos votos a favor. O CERTO seria utilizar alguma medida para corrigir isso, como: alterar o valor da probabilidade de corte a partir da curva ROC, oversampling e undersampling, ou mesmo aprendizado sensível ao erro na classe minoritária. Aí você pergunta: Por que você não fez isso?!! EU RESPONDO: provavelmente o partido e o estado sozinhos não devem fornecer informação suficiente para saber o voto do deputado e também provavelmente os decididos também não devem representar tão bem os indecisos…LOGO não valia tanto a pena perder tempo com isso. Eu só queria mesmo dar uma olhada e tentar obter alguns valores que eu não vi no post do Regis.
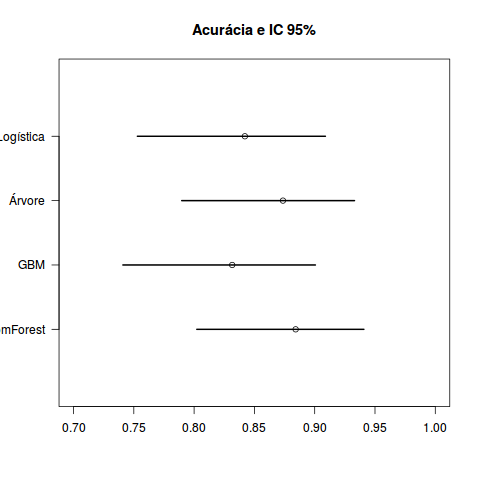
Outra dúvida que eu tinha ficado é se utilizar outras técnicas traria algum ganho, e pelo intervalos de confiança acima, considerando os quatro métodos, parece que não. Veja que existem vários valores plausíveis em comum para a acurácia global tal que eu não alegaria que nenhum método é melhor que o outro. Vejam que de fato o ranfomForest teve um desempenho no teste em torno de 90%.
Por fim, um modelo como o randomForest, apesar de ser um ensemble, provê uma medida, em termos de ganho de informação, com a qual é possível ter uma ideia das importâncias das variáveis:
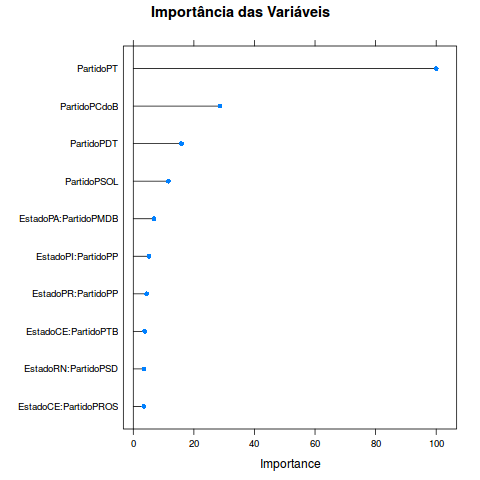
Selecionei somente as 10 mais importantes e naturalmente os partidos PT, PCdoB e etc, tem uma influência muito grande. Você pode pensar da seguinte maneira: se eu sei que um deputado é deste partido com certeza ele vota de um dos lados. O RF infelizmente não indica de que forma é essa influência, mas como fizemos uma análise exploratória, é fácil saber que quando um deputado é do PT ele vota contra o impeachment. Vejam que interessante as interações entre PMDB e o estado do PA. Isso deve ser sinal que muitos deputados daquele estado, que são do PMDB, provavelmente votam mais de um lado do que do outro.
Previsões
Agora que temos alguns modelos, vamos utilizar o randomForest e fazer algumas previsões para os indecisos. De acordo com esse modelo, teremos 66 deputados a favor e 30 contra, tal que somando o total de 265 a favor que já existem, temos um total de 331 dos 513 que devem votar a favor do impeachment. Isso dá aproximadamente 64% da câmara, tal que nesse caso a presidente sofreria o impeachment.
Conclusão
Dá para acreditar nessa previsão? EU DIRIA QUE NÃO. Isso ocorre por várias razões, mas dentre elas eu destacaria o fato de que não é só o partido e o estado que orientam a decisão de um deputado. Existem deputados na câmara com muito mais influência, tal que o voto de muitos pode estar condicionado a decisão do líder de um grupo. ASSIM, talvez seja necessário incluir alguma medida de influência no modelo. Talvez uma abordagem mais confiável seria verificar os grupos de deputados que tem votado junto recentemente, isto é, tentar prever o voto dos indecisos não com variáveis como o partido ou o estado, mas utilizando os “vizinhos mais próximos” em termos de perfil de votação. Mas de qualquer forma os gráficos revelam mais ou menos como está a câmara e meu palpite é que a presidente não sobrevive ao impeachment, PELO MENOS NA CÂMARA.
[…] Barros, do site (R Mining) fez diversas ponderações ao método do Prof. Régis que valem a leitura. Destacamos aqui sua […]
[…] Barros, do site (R Mining) fez diversas ponderações ao método do Prof. Régis que valem a leitura. Destacamos aqui sua […]