OBS: This is a full translation of a portuguese version.
In many different types of experiments, with one or more treatments, one of the most widely used statistical methods is analysis of variance or simply ANOVA . The simplest ANOVA can be called “one way” or “single-classification” and involves the analysis of data sampled from more then one population or data from experiments with more than two treatments.
It’s not my intent to study in depth the ANOVA, but to show how to apply the procedure in R and apply a “post-hoc” test called Tukey’s test. When we are conducting an analysis of variance, the null hypothesis considered is that there is no difference in treatments mean, so once rejected the null hypothesis, the question is what treatment differ.
To illustrate the procedure we consider an experimental situation where a company is applying a sensory test for a set of 15 panelists in three different brands of chocolate. Three brands are compared, one being the reference, and the goal is to verify the difference of marks with the control. In this experiment we have two factors, the brand and the tasters, and we hope that there is no significant effect of tasters. At each assessment the assessor must determine the difference on a scale 0-7.
data.frame(
Sabor =
c(5, 7, 3,
4, 2, 6,
5, 3, 6,
5, 6, 0,
7, 4, 0,
7, 7, 0,
6, 6, 0,
4, 6, 1,
6, 4, 0,
7, 7, 0,
2, 4, 0,
5, 7, 4,
7, 5, 0,
4, 5, 0,
6, 6, 3
),
Tipo = factor(rep(c("A", "B", "C"), 15)),
Provador = factor(rep(1:15, rep(3, 15))))
The average grade for types A, B and C were respectively 5.33 5.27 and 1.53. Clearly C, the control, was not different for most of the tasters, as expected. One way to easily obtain these averages per group is using tapply.
tapply(chocolate$Sabor, chocolate$Tipo, mean)
Finally we run ANOVA and assess whether there are differences between brands and tasters.
ajuste <- lm(chocolate$Sabor ~ chocolate$Tipo + chocolate$Provador) summary(ajuste) anova(ajuste)
what results:
Analysis of Variance Table
Response: chocolate$Sabor
Df Sum Sq Mean Sq F value Pr(>F)
chocolate$Tipo 2 141.911 70.956 19.21 5.598e-06 ***
chocolate$Provador 14 32.578 2.327 0.63 0.8175
Residuals 28 103.422 3.694
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
From the output we see that the p-value is 0.8175 for tasters indicating that the assessors have no significant effect on the response. This is desirable since it is expected that the testers can discern correctly the marks of chocolate. Also in the table we see that the ANOVA p-value for the type of chocolate is highly significant, indicating the difference between the marks. So from now on we can make the Tukey test to see where the differences lie.
a1 <- aov(chocolate$Sabor ~ chocolate$Tipo + chocolate$Provador) posthoc <- TukeyHSD(x=a1, 'chocolate$Tipo', conf.level=0.95)
that results:
Tukey multiple comparisons of means
95% family-wise confidence level
Fit: aov(formula = chocolate$Sabor ~ chocolate$Tipo + chocolate$Provador)
$`chocolate$Tipo`
diff lwr upr p adj
B-A -0.06666667 -1.803101 1.669768 0.9950379
C-A -3.80000000 -5.536435 -2.063565 0.0000260
C-B -3.73333333 -5.469768 -1.996899 0.0000337
This output indicates that the differences C-A and C-B are significant , while B-A is not significant. A more “easy” way to interpret this output is visualizing the confidence intervals for the mean differences.
plot(a1)
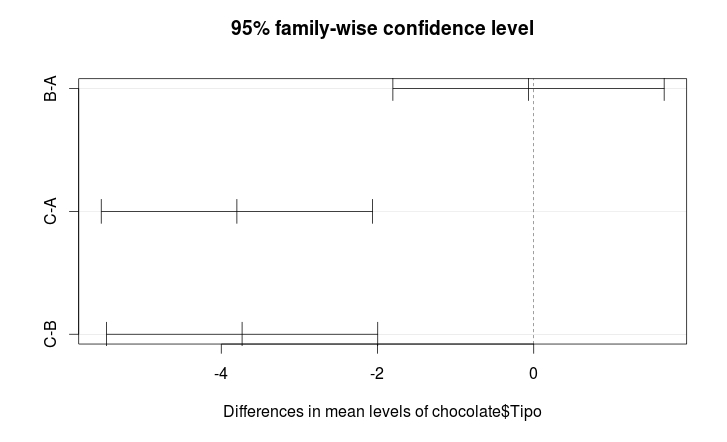
One can see that only the confidence interval for B-A contain 0. Thus, it appears that the marks A and B do not differ among themselves, but are different from brand control.
Finally an alternative way to evaluate the differences in a way more similar to the SAS is using the package agricolae. With it we will apply the same procedure, but the output is slightly different.
library(agricolae) HSD.test(ajuste, 'chocolate$Tipo')
Study: HSD Test for chocolate$Sabor Mean Square Error: 3.693651 chocolate$Tipo, means chocolate.Sabor std.err r Min. Max. A 5.333333 0.3737413 15 2 7 B 5.266667 0.4078593 15 2 7 C 1.533333 0.5844547 15 0 6 alpha: 0.05 ; Df Error: 28 Critical Value of Studentized Range: 3.49926 Honestly Significant Difference: 1.736435 Means with the same letter are not significantly different. Groups, Treatments and means a A 5.333 a B 5.267 b C 1.533
where the final output indicates that both A and B belong to the same group, the ‘a’, and C is different from the other two, belongs to the group ‘b’.
[…] ANOVA and Tukey's test on R | Flavio Barros […]
…Trackback: More Informations on that topic
[…]you make blogging glance[…]