A linguagem R oferece ferramentas que podem ser usadas para visualização, modelagem e leitura de bancos de dados. Mas uma de suas características mais importantes é que é uma excelente ferramenta para preparação de dados. Naturalmente, como em outras linguagens, existem alguns truques que podem (e devem!) ser utilizados para melhorar a performance das tarefas, e especialmente no caso do R essas escolhas tem um impacto gigantesco na performance do scripts. Assim, neste post vou apresentar alguns dos truques mais importantes que devem ser utilizados no R e também vou apresentar um método muito importante na preparação que é o split-apply-recombine.
1. Usando o apply, lappy, tapply
Algumas vezes os apply’s podem deixar o código mais rápido ou no mínimo eliminar alguns for’s deixando o código mais legível. O fato é que, pelo menos no R, é fortemente aconselhável evitar o uso do for. Dessa forma, ao invés de usar o for é melhor executar as interações em matrizes, listas e data.frames usando a família apply. Um exemplo:
matriz <- matrix(round(runif(9,1,10),0),nrow=3) apply(matriz, 1, sum) ## sum by row apply(matriz, 2, sum) ## sum by column
Particularmente neste exemplo você pode não ter um ganho de performance, mas o código pelo menos fica um pouco mais legível.
Já que estamos falando de médias, o tapply é especialmente útil na tarefa de obter médias por grupo. A seguir um exemplo onde você consegue tirar uma média para grupos em uma única linha:
mpg cyl disp hp drat wt qsec vs am gear carb Mazda RX4 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4 Mazda RX4 Wag 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4 Datsun 710 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1 Hornet 4 Drive 21.4 6 258.0 110 3.08 3.215 19.44 1 0 3 1 Hornet Sportabout 18.7 8 360.0 175 3.15 3.440 17.02 0 0 3 2 Valiant 18.1 6 225.0 105 2.76 3.460 20.22 1 0 3 1 Duster 360 14.3 8 360.0 245 3.21 3.570 15.84 0 0 3 4 Merc 240D 24.4 4 146.7 62 3.69 3.190 20.00 1 0 4 2 Merc 230 22.8 4 140.8 95 3.92 3.150 22.90 1 0 4 2 Merc 280 19.2 6 167.6 123 3.92 3.440 18.30 1 0 4 4 Merc 280C 17.8 6 167.6 123 3.92 3.440 18.90 1 0 4 4 Merc 450SE 16.4 8 275.8 180 3.07 4.070 17.40 0 0 3 3 Merc 450SL 17.3 8 275.8 180 3.07 3.730 17.60 0 0 3 3 Merc 450SLC 15.2 8 275.8 180 3.07 3.780 18.00 0 0 3 3 Cadillac Fleetwood 10.4 8 472.0 205 2.93 5.250 17.98 0 0 3 4 Lincoln Continental 10.4 8 460.0 215 3.00 5.424 17.82 0 0 3 4 Chrysler Imperial 14.7 8 440.0 230 3.23 5.345 17.42 0 0 3 4 Fiat 128 32.4 4 78.7 66 4.08 2.200 19.47 1 1 4 1 Honda Civic 30.4 4 75.7 52 4.93 1.615 18.52 1 1 4 2 Toyota Corolla 33.9 4 71.1 65 4.22 1.835 19.90 1 1 4 1 Toyota Corona 21.5 4 120.1 97 3.70 2.465 20.01 1 0 3 1 Dodge Challenger 15.5 8 318.0 150 2.76 3.520 16.87 0 0 3 2 AMC Javelin 15.2 8 304.0 150 3.15 3.435 17.30 0 0 3 2 Camaro Z28 13.3 8 350.0 245 3.73 3.840 15.41 0 0 3 4 Pontiac Firebird 19.2 8 400.0 175 3.08 3.845 17.05 0 0 3 2 Fiat X1-9 27.3 4 79.0 66 4.08 1.935 18.90 1 1 4 1 Porsche 914-2 26.0 4 120.3 91 4.43 2.140 16.70 0 1 5 2 Lotus Europa 30.4 4 95.1 113 3.77 1.513 16.90 1 1 5 2 Ford Pantera L 15.8 8 351.0 264 4.22 3.170 14.50 0 1 5 4 Ferrari Dino 19.7 6 145.0 175 3.62 2.770 15.50 0 1 5 6 Maserati Bora 15.0 8 301.0 335 3.54 3.570 14.60 0 1 5 8 Volvo 142E 21.4 4 121.0 109 4.11 2.780 18.60 1 1 4 2
com
tapply(mtcars$hp, mtcars$cyl, mean)
e você tem a média da potência por capacidade do cilindro. Esta função é extremamente útil em análise descritiva, principalmente quando você tem uma variável numérica que deve ser resumida em função de outra variável categórica. Entretanto algumas vezes temos listas e não vetores tal que é necessário fazer uso do lapply. Vamos gerar dados de exemplo:
lista <- list(a=c('one', 'tow', 'three'), b=c(1,2,3), c=c(12, 'a'))
Cada elemento na lista é um vetor. Digamos que você queira saber quantos elementos existem em cada vetor, mas sem usar um for! Vejamos:
lapply(lista, length) ## return a list sapply(lista, length) ## coerce to a vector
$a [1] 3 $b [1] 3 $c [1] 2
a b c 3 3 2
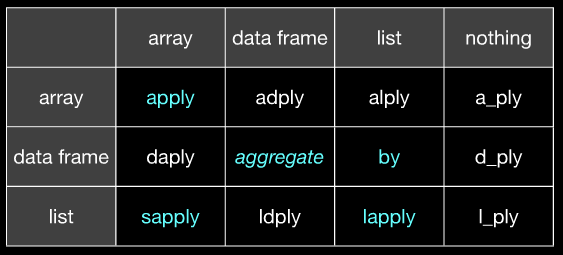
2. Split, apply and recombine
Esta é uma técnica que simplesmente DEVE SER CONHECIDA. É o fundamento por detrás de pacotes como o plyr e dplyr e é a mesma estratégia utilizada no MapReduce. Aqui vou usar somente funções do pacote base mas em outra oportunidade planejo apresentar as vantagens de fazer isso com dplyr. Voltando para o conjunto de dados mtcars, suponha que queiramos ajustar modelos de regressão da variável mpg (milha por galão) contra disp, agrupado por gears, e então comparar os coeficientes das regressões. Como fazemos isso?

data <- split(mtcars, mtcars$gear) ## split fits <- lapply(data, function(x) return(lm(x$mpg~x$disp)$coef)) ## apply do.call(rbind, fits) ## recombine
(Intercept) x$disp 3 24.51557 -0.02577046 4 39.56753 -0.12221268 5 31.66095 -0.05077512
Como você pode ver, em três passos está pronto: separa, aplica e agrega. É uma técnica poderosa que pode ser aplicada em diferentes contextos. Veja que o tapply usa esta estratégia internamente para calcular as médias por grupo: split no grupo, aplica a função média, junta as médias para apresentar no final.
Você conseguiria reproduzir o resultado do tapply com o split e o sapply? Poste nos comentários!